Data/머신러닝
데이터 전처리 기법 알아보기 (python)
민 채
2025. 5. 15. 11:29
📌 1. 결측치 처리 (Missing Value Imputation)
데이터 불러오기
import pandas as pd
import numpy as np
dat = pd.read_csv('https://raw.githubusercontent.com/YoungjinBD/data/main/dat.csv')
y = dat.grade
X = dat.drop(['grade'], axis = 1)
# 각 칼럼별 속성 확인
print(X.info())
print(y.info())
# 결측치 확인
print(dat.isna().sum(axis = 0))
# 학습 데이터와 테스트 데이터 분리
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(
X,
y,
test_size = 0.2,
random_state = 0,
shuffle = True,
stratify = None
)
1.1 평균, 중앙값, 최빈값 대치
통계량을 이용해 빠르게 대치가 가능하다.
from sklearn.impute import SimpleImputer
train_X1 = train_X.copy()
test_X1 = test_X.copy()
# mean으로 대치
imputer_mean = SimpleImputer(strategy = 'mean')
# 데이터에 적용
train_X1['goout'] = imputer_mean.fit_transform(train_X1[['goout']])
test_X1['goout'] = imputer_mean.transform(test_X1[['goout']])
print('학습 데이터 goout 변수 결측치 확인 :', train_X1['goout'].isna().sum())
print('테스트 데이터 goout 변수 결측치 확인 :', test_X1['goout'].isna().sum())
mean: 연속형 변수에 사용median: 이상치가 있을 때 추천most_frequent: 범주형 변수에 사용
⚠️ 반드시 훈련 데이터의 통계량으로 테스트 데이터도 처리해야 함 → 데이터 누수 방지
데이터 누수: 학습 데이터에 포함된 정보가 테스트 데이터에 포함되는 것
1.2 KNN을 활용한 결측치 대치
from sklearn.impute import KNNImputer
train_X5 = train_X.copy()
test_X5 = test_X.copy()
# 수치형 변수와 범주형 변수를 나누어 대치
train_X5_num = train_X5.select_dtypes('number')
test_X5_num = test_X5.select_dtypes('number')
train_X5_cat = train_X5.select_dtypes('object')
test_X5_cat = test_X5.select_dtypes('object')
# KNNImputer는 수치형 변수에만 적용 가능
# k값에 따라서 대치 결과가 달라질 수 있음 => k값을 조정하여 성능을 높일 수 있음
knnimputer = KNNImputer(n_neighbors = 5)
train_X5_num_imputed = knnimputer.fit_transform(train_X5_num)
test_X5_num_imputed = knnimputer.transform(test_X5_num)
# sklearn은 numpy로 output이 나오기 때문에 DataFrame으로 변환해줘야 한다.
train_X5_num_imputed = pd.DataFrame(train_X5_num_imputed,
columns=train_X5_num.columns,
index = train_X5.index)
test_X5_num_imputed = pd.DataFrame(test_X5_num_imputed,
columns=test_X5_num.columns,
index = test_X5.index)
train_X5 = pd.concat([train_X5_cat, train_X5_num_imputed], axis = 1)
test_X5 = pd.concat([test_X5_cat, test_X5_num_imputed], axis = 1)
print('학습 데이터 goout 변수 결측치 확인 :', train_X5['goout'].isna().sum())
print('테스트 데이터 goout 변수 결측치 확인 :', test_X5['goout'].isna().sum())
# set_output() 메서드를 활용하면 추가적인 코드 작성 없이 pandas 데이터프레임으로 변환할 수 있습니다.
knnimputer2 = KNNImputer(n_neighbors = 5).set_output(transform = 'pandas')
train_X5_num_imputed2 = knnimputer2.fit_transform(train_X5_num)
test_X5_num_imputed2 = knnimputer2.transform(test_X5_num)
# 판다스 데이터프레임 출력
print(train_X5_num_imputed2.head())
print('학습 데이터 goout 변수 결측치 확인 :', train_X5_num_imputed2['goout'].isna().sum())
print('테스트 데이터 goout 변수 결측치 확인 :', test_X5_num_imputed2['goout'].isna().sum())- 주변 이웃(k개)의 평균으로 결측치를 대치
- 데이터에 대한 가정없이 쉽고 빠르게 대치할 수 있지만,
- 고차원 데이터의 경우 성능이 떨어질 수 있고 스케일/이상치에 민감하다.
📌 2. 범주형 변수 인코딩 (Categorical Encoding)
2.1 라벨 인코딩 (OrdinalEncoder)
범주형 변수의 각 label에 알파벳 순서대로 고유한 정수를 할당하는 방법
from sklearn.preprocessing import OrdinalEncoder
train_X6 = train_X.copy()
test_X6 = test_X.copy()
train_X6_cat = train_X6.select_dtypes('object')
test_X6_cat = test_X6.select_dtypes('object')
ordinalencoder = OrdinalEncoder().set_output(transform = 'pandas')
train_X6_cat = ordinalencoder.fit_transform(train_X6_cat)
test_X6_cat = ordinalencoder.fit_transform(test_X6_cat)
print(train_X6_cat.head(2))- 순서형 변수의 경우 순서를 반영한 인코딩이 가능함
- 주의: 모델은 정수 간의 크기 정보를 학습함
테스트 데이터에는 있지만 훈련 데이터에는 없는 범주가 있을 수 있다.
# 훈련 데이터
train_data = pd.DataFrame({
'job': ['Doctor', 'Engineer', 'Teacher', 'Nurse']
})
# 테스트 데이터
test_data = pd.DataFrame({
'job': ['Doctor', 'Lawyer', 'Teacher', 'Scientist']
})
# 학습되지 않은 카테고리를 처리할 때 오류를 발생시키지 않고 unknown_value로 대치
oe = OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1)
# 훈련 데이터로 인코더 학습
oe.fit(train_data[['job']])
# 훈련 데이터 변환
train_data['job_encoded'] = oe.transform(train_data[['job']])
# 테스트 데이터 변환 (훈련 데이터에 없는 직업은 -1로 인코딩됨)
test_data['job_encoded'] = oe.transform(test_data[['job']])
print(train_data)
print(test_data)
2.2 원-핫 인코딩 (OneHotEncoder)
from sklearn.preprocessing import OneHotEncoder
train_X7 = train_X.copy()
test_X7 = test_X.copy()
train_X7_cat = train_X7.select_dtypes('object')
test_X7_cat = test_X7.select_dtypes('object')
onehotencoder = OneHotEncoder(sparse_output = False,
handle_unknown = 'ignore').set_output(transform = 'pandas')
train_X7_cat = onehotencoder.fit_transform(train_X7_cat)
test_X7_cat = onehotencoder.transform(test_X7_cat)
print(train_X7_cat.head())
print(test_X7_cat.head())- 각 범주마다 새로운 컬럼 생성
- 장점: 라벨 인코딩의 문제점인 수치 정보 반영 문제 해결 가능
- 단점: 범주 수가 많으면 차원 폭발 발생 (메모리 사용량 폭증)
2.3 더미 인코딩
원 핫 인코딩과 비슷하지만, 기준범주를 제외한 나머지 범주에 대해서만 더미변수를 생성한다는 점이 다르다. (drop = 'first')
train_X8 = train_X.copy()
test_X8 = test_X.copy()
train_X8_cat = train_X8.select_dtypes('object')
test_X8_cat = test_X8.select_dtypes('object')
# drop = 'first' : 첫 번째 범주를 기준범주로 설정
# handle_unknown = 'error' : 훈련 데이터에 없는 범주가 테스트 데이터에 있는 경우 오류 발생
dummyencoder = OneHotEncoder(sparse_output = False,
drop = 'first',
handle_unknown = 'error').set_output(transform = 'pandas')
train_X8_cat = dummyencoder.fit_transform(train_X8_cat)
test_X8_cat = dummyencoder.transform(test_X8_cat)
print(train_X8_cat.head())
📌 3. 데이터 정규화 (Scaling)
분포의 치우침이 있을 때, 변수 변환을 통해 정규분포 형태로 변환하는 것을 고려할 수 있다.
단, 해석을 하려면 다시 원데이터로 변환해야 한다.
데이터 불러오기
dat = pd.read_csv('https://raw.githubusercontent.com/YoungjinBD/data/main/dat.csv')
y = dat.grade
X = dat.drop(['grade'], axis = 1)
# 각 칼럼별 속성 확인
print(X.info())
print(y.info())
# 결측치 확인
print(dat.isna().sum(axis = 0))
# 학습 데이터와 테스트 데이터 분리
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(
X,
y,
test_size = 0.2,
random_state = 0,
shuffle = True,
stratify = None
)
3.1 표준화 (StandardScaler)
from sklearn.preprocessing import StandardScaler
train_X9 = train_X.copy()
test_X9 = test_X.copy()
train_X9_num = train_X9.select_dtypes('number')
test_X9_num = test_X9.select_dtypes('number')
stdscaler = StandardScaler().set_output(transform = 'pandas')
train_X9_num = stdscaler.fit_transform(train_X9_num)
test_X9_num = stdscaler.transform(test_X9_num)
print(train_X9_num.head(2))
print('변환 전 평균 :', np.round(train_X9['absences'].mean()), sep = '\n')
print('변환 후 평균 :', np.round(train_X9_num['absences'].mean()), sep = '\n')
- 평균 0, 표준편차 1로 변환
- SVM, KNN 등 거리 기반 알고리즘에 유리
- 이상치에 민감
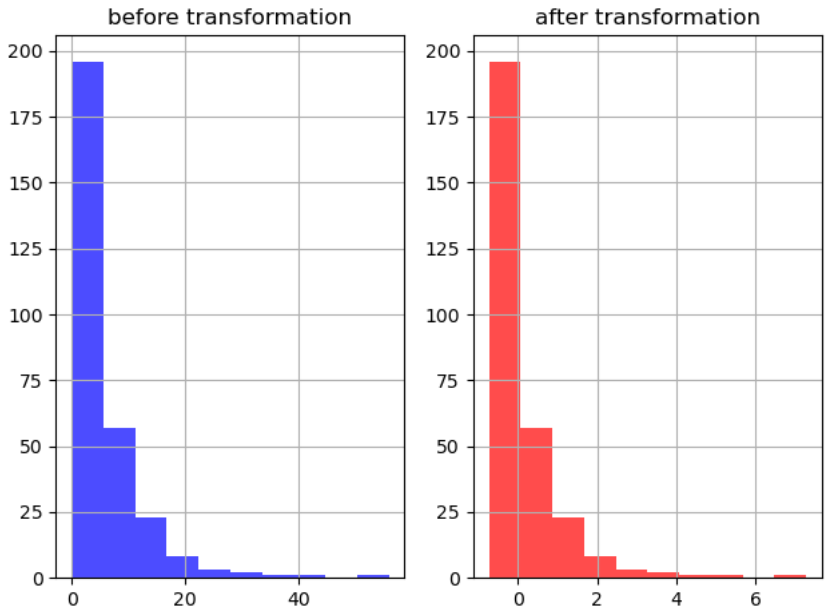
- 변수의 스케일을 통일 시켜주는 거지 분포의 형태를 바꾸지는 않음
3.2 Min-Max 정규화
데이터의 최소값과 최대값을 이용하여 0~1 사이로 변환
단점: 이상치가 있을 경우 값이 너무 작아지거나 커질 수 있음
from sklearn.preprocessing import MinMaxScaler
train_X10 = train_X.copy()
test_X10 = test_X.copy()
train_X10_num = train_X10.select_dtypes('number')
test_X10_num = test_X10.select_dtypes('number')
minmaxscaler = MinMaxScaler().set_output(transform = 'pandas')
train_X10_num = minmaxscaler.fit_transform(train_X10_num)
test_X10_num = minmaxscaler.transform(test_X10_num)
range_df = train_X10_num.select_dtypes('number').apply(lambda x: x.max() - x.min(), axis=0)
print("\nRange of each column:")
print(range_df)3.3 분포 변환 (Box-Cox / Yeo-Johnson)
치우친 분포 → 정규 분포로 바꿔준다.
Box-Cox: 값 > 0 에만 사용 가능Yeo-Johnson: 음수 값도 지원
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 실습 데이터 불러오기
bike_data = pd.read_csv("https://raw.githubusercontent.com/YoungjinBD/data/main/bike_train.csv")
from sklearn.preprocessing import PowerTransformer
box_tr = PowerTransformer(method = 'box-cox')
bike_data['count_boxcox'] = box_tr.fit_transform(
bike_data[['count']])
print('lambda : ', box_tr.lambdas_)
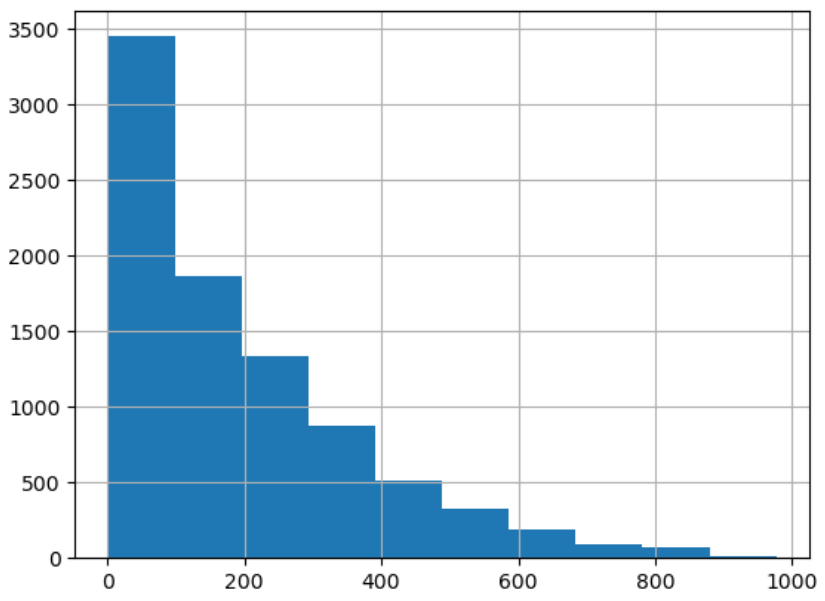
시각화
원래 데이터
변환한 데이터
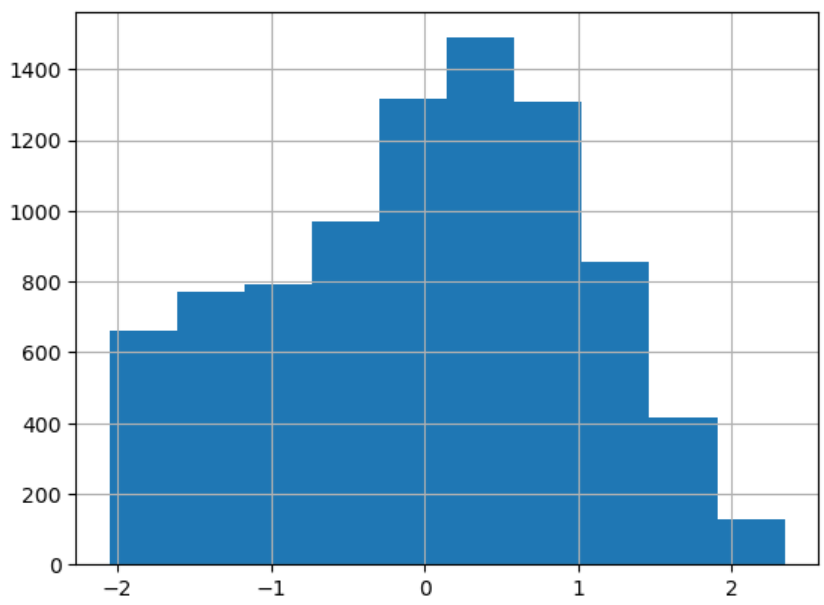
- 치우친 분포가 중앙으로 모인 모습을 볼 수 있다.
📌 4. 수치형 변수 이산화 (Binning)
import numpy as np
import pandas as pd
X = np.array([[0, 1, 1, 2, 5, 10, 11, 14, 18]]).T
# 구간의 길이가 같도록 이산화하는 방법
from sklearn.preprocessing import KBinsDiscretizer
kbd2 = KBinsDiscretizer(n_bins = 4,
strategy = 'quantile') # 사분위수를 기준으로 이산화
X_bin2 = kbd2.fit_transform(X).toarray()
print(kbd2.bin_edges_)
- 연속형 변수 → 구간화
uniform: 동일한 간격quantile: 사분위수 기반
또는, pd.cut() 을 이용해서 사용자 정의 구간화도 가능하다
bins = [0, 4, 7, 11, 18]
labels = ['A', 'B', 'C', 'D']
X_bin3 = pd.cut(X.reshape(-1),
bins = bins,
labels = labels)
print(X_bin3)
📌 5. 범주형 변수 축소
freq = train['weather'].value_counts(normalize=True)
rare = freq[freq < 0.1].index
train['weather'] = train['weather'].replace(rare, 'other')- 빈도수가 낮은 범주를 통합하여 모델 복잡도 감소
- 모델의 일반화 성능 향상
📌 6. 이상치 처리 (Outlier Detection)
6.1 IQR 방식
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
warpbreaks = pd.read_csv('https://raw.githubusercontent.com/YoungjinBD/data/main/warpbreaks.csv')
# 1분위수 계산
Q1 = np.quantile(warpbreaks['breaks'], 0.25)
# 3분위수 계산
Q3 = np.quantile(warpbreaks['breaks'], 0.75)
IQR = Q3 - Q1
UC = Q3 + (1.5 * IQR) # 위 울타리
LC = Q3 - (1.5 * IQR) # 위 울타리
print(warpbreaks.loc[(warpbreaks.breaks > UC) | (warpbreaks.breaks < LC), :])
6.2 Z-Score 방식
upper = warpbreaks['breaks'].mean() + (3*warpbreaks['breaks'].std())
lower = warpbreaks['breaks'].mean() - (3*warpbreaks['breaks'].std())
warpbreaks.loc[(warpbreaks.breaks > upper) | (warpbreaks.breaks < lower), :].head(3)
# 이상치 여부 컬럼 추가
warpbreaks['z_outlier'] = warpbreaks['breaks'].apply(lambda x: 'Outlier' if x > upper or x < lower else 'Normal')